My talk begins at 0:35.
My code can be found here and a blog post discussing the project in further detail is here.
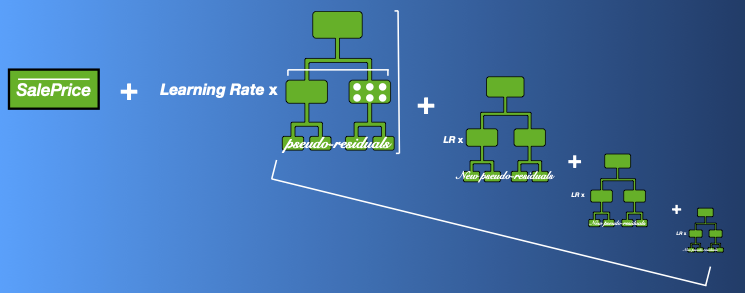
Implemented multiple machine learning models in Python and Scikit-learn to predict house prices using the Ames dataset from Kaggle. The process involved data cleaning and preparation, feature engineering, preprocessing, and modeling. Models included Linear Regression, Penalized Linear Regression, Support Vector Machines, Random Forests, and Gradient Boosting.
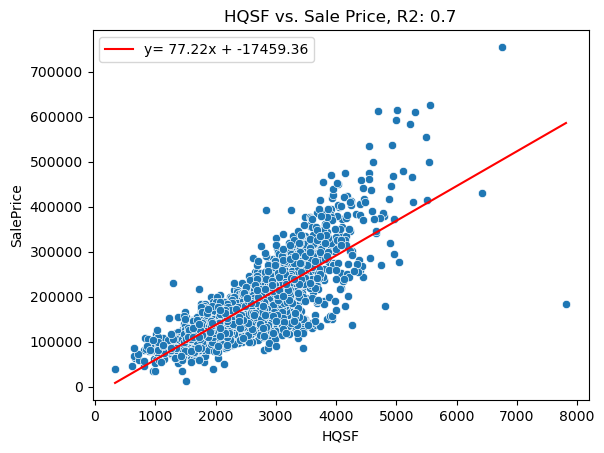
My approach highlighted the trade-offs between accuracy and interpretability in ML models. Multiple Linear Regression was my endpoint of interpretability over accuracy, while Gradient Boosting was my endpoint of accuracy over interpretability. By doing a deep dive on these two models, I illustrate the endpoints of accessibility and accuracy in order to inform realtors and home buyers and sellers about the best ways to approach the real estate market. My analysis suggests that big factors like square footage and number of bedrooms and bathrooms factors into home prices, but preparing the data with subtler interactions like “rooms multiplied by bedrooms” can help ML models discover deeper differences between similar homes and yield more accurate sale price predictions.